It’s a fun programming puzzle to try to figure out the fewest characters needed to express a program—generally known as “code golf.” In some past articles [1] [2], I’ve looked at how to minimize the number of bytes needed for a program. However, it’s an equally interesting question as to how many Unicode characters are needed. Because there are many more Unicode characters than bytes (1,112,064 code points are valid, though only ~155K are currently assigned a meaning), using Unicode opens up all kinds of possibilities for squeezing in more data in each character.
In this article, we’ll look at some techniques for how ordinary JavaScript code can be packed into a shorter program using Unicode. We’ll start with an explanation of the conventional 2:1 (un)packer: a clever piece of code that packs two ASCII characters into each Unicode character. Then, I’ll show some variations I developed that can sometimes save a few characters, which I’ve dubbed the “2:1-plus packer.” The code is available on GitHub.
The 2:1 unpacker
The original source for the 2:1 unpacker comes from here. It’s widely used for code golf problems, such as on code.golf, that are scored in Unicode characters. Although it’s not the only packing technique available, it tends to be the best for short programs (up to 200+ bytes before packing). Here’s an example of some code before and after packing:
//Before (93 characters)
console.log("Lorem ipsum dolor sit amet, consectetur adipiscing elit, sed do eiusmod tempor")
//After (90 characters)
eval(unescape(escape`c𫱮𬱯𫁥𫱧𣁯𬡥𫐠𪑰𬱵𫐠𩁯𫁯𬠠𬱩𭀠𨑭𩑴𛀠𨱯𫡳𩑣𭁥𭁵𬠠𨑤𪑰𪑳𨱩𫡧𘁥𫁩𭀬𘁳𩑤𘁤𫰠𩑩𭑳𫑯𩀠𭁥𫑰𫱲𘠩`.replace(/uD./g,``)))Before diving into how this works, a brief explanation of Unicode and JavaScript: when JavaScript was created many years ago, all Unicode characters could fit into 16 bits. So, like many other systems and programming languages of the time, JavaScript decided to use 16 bits to represent the characters of a string. However, Unicode eventually grew large enough that 16 bits wasn’t enough to hold all characters, and so surrogate pairs were developed as a solution to encode more characters. That means some Unicode characters are represented as two JavaScript characters. For example,
s = "😀" //one Unicode character
s.length === 2 //appears as 2 JavaScript characters
s.charCodeAt(0) === 0xD83D
s.charCodeAt(1) === 0xDE00The 2:1 (un)packer exploits this behavior to turn one Unicode character into two bytes—without needing any code to explicitly do the two-for-one split.
Let’s go through step-by-step what the unpacker is doing:
eval(unescape(escape`𪁩`.replace(/uD./g,'')))
^^^^^^^^^^It begins by using the (deprecated, but still there) function escape to convert Unicode characters into ASCII strings—in this case, "%uD868%uDC69", where the two %u halves represent the two surrogate pairs making up the character 𪁩. Note that the use of backticks `` is a golf trick: this usage of tagged templates saves 2 bytes compared to using parentheses to call the function with a string. The tagged template syntax has the effect of calling escape(["𪁩"]). The first argument ["𪁩"] is coerced to a string by the function, and an array of one string coerces to that string, so it’s equivalent to escape("𪁩").
Next,
eval(unescape("%uD868%uDC69".replace(/uD./g,'')))
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^This is the crux of the unpacker: a regex removes the upper bits of each escaped character, leaving the string "%68%69". We’ve gone from Unicode-style escapes %uHHHH to byte-style escapes %HH, and our surrogates become ordinary bytes—a nice trick! Fortunately, we can fit any 8-bit value into the last two hexes of Unicode surrogates: the first (high) surrogate can cover anything in the range D800–DBFF and the second (low) can cover anything in DC00–DFFF.
(Note that sometimes the regex /u../g is used instead of /uD./g. It has the exact same effect for converting surrogates to bytes, since the hex representation of surrogates always begin with D. However, if the original source has Unicode in it, the different regexes matter—we’ll discuss this issue later!)
Next, we finish the unpacking:
eval(unescape("%68%69"))
^^^^^^^^^^^^^^^^^^unescape (another deprecated function) is used to convert the escaped string "%68%69"into "hi". We got two bytes out of a single Unicode character.
Finally, eval runs the code:
eval("hi")This throws an error, since it isn’t real code, but it shows how the unpacking process works!
How to pack
Assuming our original source code is ASCII, the algorithm to pack is quite simple: we construct high and low surrogates in which the lower 8 bits match the ASCII code we’re packing. To obtain a high surrogate from an ASCII code, use the code point with hex value D8[ASCII code in hex]. (Note that the prefixes D9, DA, and DB are equally valid.) To obtain a low surrogate, use DC[ASCII code in hex]. (Again, the prefixes DD, DE, and DF are equally valid.) Then, string all the surrogates together, and that’s your packed string.
Original string| c | o | n | s | ...
ASCII hex value| 63 | 6F | 6E | 73 | ...
Surrogate hex | D863 | DC6F | D86E | DC73 | ...
Packed string | 𨱯 | 𫡳 | ...function pack_21(to_pack)
{
escaped_packed_string = [...to_pack].map((c, i) => {
ascii_value = c.charCodeAt().toString(16).padStart(2, 0);
if(i%2 == 0)
return "%uD8" + ascii_value; //high surrogate
else
return "%uDC" + ascii_value; //low surrogate
});
return unescape(escaped_packed_string.join(""));
}Going beyond 2:1
The 2:1 packer is throwing away a lot of information: a single surrogate contains 10 bits of information, but when we delete the first two hexes, we’re left with just 8 bits of information. So, there ought to be enough room to do better than 2:1 sometimes. (Indeed, a 3:1 packer is possible for ASCII code, but its higher overhead only makes it worthwhile if the original code is over 200 bytes; we won’t cover it in this article.) It also has the disadvantage that some Unicode characters cannot be packed: anything from U+D000 to U+D7FF (home to many Korean characters) will be destroyed by the replace(/uD./g,'') operation, even though they aren’t surrogates. (It’s not common to want to pack non-ASCII code, but it’s nice to have the option when needed.) So, one might ask whether the unpacker can be modified to remove these disadvantages.
We can prevent destruction of many Unicode characters by tightening up the regex used in the packer. For example, /uD[8C]/g will only match U+D800–D8FF and U+DC00–DCFF, which are always surrogate characters (high and low, respectively). Thus, our Korean characters U+D000–D7FF will survive the packer. Furthermore, many surrogates will also survive (e.g. the high surrogates U+D900–DBFF do not match the regex), allowing characters from some supplementary planes to be packed. The disadvantage is that the longer regex costs three more characters compared to the regular unpacker.
Because this is code golf, we should keep looking for shorter regexes! One trick is to “reuse” the D in the regex by targeting a different range of surrogates: the range U+DD00–DDFF also represents low surrogates, and we can match them with /uD+8?/g, which is one character shorter. This has the disadvantage that it matches more strings, so it’ll destroy more Unicode (e.g. we’ve lost our Korean characters because it matches everything that starts with the prefix %uD), but perhaps it’s still useful in some situations.
Now, for the most important trick—this is where analyzing corner cases and reading the docs carefully paid off. Consider what happens to the escaped surrogates "%uD868%uDDD1" after applying replace(/uD+8?/g,""): we’ll be left with %68%1. The %68 will become "h" after unescape, but what happens to %1? As per the docs:
If the escape sequence is not a valid escape sequence (for example, if
%is followed by one or no hex digit), it is left as-is.
Therefore, %1 remains as %1. That means "%uD868%uDDD1"—which came from a single Unicode character—unpacks to three bytes, "h%1". We’re doing better than 2:1!
With this trick in mind—and forgetting about packing non-ASCII characters—we can optimize the regex even more, using /u\D*/g instead (the \D means non-digits). This regex can do 2:1 packing of ASCII by matching the first two hexes of high surrogates U+DA00–DA7F, and of low surrogates U+DC00–DC7F. It’s only 1 character longer than the standard 2:1 packer’s regex, and there are several situations where it attains 3:1 packing:
- As we already saw, we can produce the three characters
[any ASCII][%][any digit]from a single character corresponding to%uDA[ASCII code]%uDDD[digit].[%][any digit][any ASCII]can be done similarly. - We can produce the three characters
[any ASCII][any hex digit][any hex digit]from a single character corresponding to%u[ASCII code][hex digit][hex digit]. (Interestingly, this trick doesn’t involve surrogates.) For example,%u3123becomes%3123after the replace. The%31unescapes to1, and the23remains as it is, yielding"123". - 4:1 is even possible in one case:
[%][any digit][%][any digit].
Generally speaking, this regex will be effective on programs that have runs of characters from 0123456789ABCDEF%. In particular, programs with a lot of numbers tend to pack well.
Packer plus
We’ve seen that using alternative regexes gives us options for packing more Unicode characters or packing digits more efficiently. The next step is writing a program to perform the packing! I’ve posted my packer on GitHub, and I’ll give a brief description below.
The packer is no longer straightforward due to the variable rate of packing. I chose to use a generic approach at the expense of time and memory. We start by building a table of what every Unicode character unpacks to. This is the expensive step, as there are over a million characters—although with how fast computers are, a million isn’t anything we can’t handle!
//Note: this is a simplified version
const char_map = new Map();
for(let j = 0; j < 1112064; ++j)
{
//Skip Unicode surrogates
if(0xD800 <= j && j <= 0xDFFF)
continue;
let c = String.fromCodePoint(j);
//What does the character unpack to?
const q = unescape(escape(c).replace(regex,""));
if(!char_map.has(q))
char_map.set(q, c);
}(This function is significantly optimized in the GitHub code. To reduce the amount of work with code points above U+FFFF—that is, those that break down into surrogates—we do surrogates separately (1024 each of high and low) and prune the ones that aren’t useful. Then, only the useful surrogates are recombined and put into char_map.)
Then, we use a standard dynamic programming approach to find the optimal sequence of characters for packing. Mathematically, if we define \(P(n)\) to be the optimal packing of the first n source characters, then
\(\displaystyle P(n) = 1+\min_{\{i:\mathrm{Packable}(n,i)\}} P(n-i)\)
where Packable(n,i) means there is a Unicode character that unpacks to the substring from (n-i+1) to n (inclusive) of the source.
//state[N] is the optimal packing so far, with N more source characters already packed
let state = [{str: "", cost: 0}];
for(const i in to_pack)
{
//Try possible next characters in the packing for state[0]
if(state[0] !== undefined)
{
for(let l = 1; l <= 4; l++)
{
const target = to_pack.slice(i,+i+l);
const packed_char = char_map.get(target);
if(packed_char !== undefined)
{
const str1 = state[0].str + packed_char;
const cost1 = state[0].cost + 1;
if(cost1 < (state[l]?.cost ?? Infinity))
state[l] = {str: str1, cost: cost1};
}
}
}
//Advance one (unpacked) character
state.shift();
}
//Now state[0] holds the best pack(Is dynamic programming necessary, or would a greedy algorithm work? I’m not aware of any cases where the greedy algorithm wouldn’t be optimal for /uD./g or /u\D*/g—though I don’t have a proof, so I might have missed something. On the other hand, there are some edge cases with /uD[8C]/g. For example, for the string "ababab\", the greedy algorithm will pack it as (ab)(ab)(ab)(\), and the \ requires an escaped character to pack, costing a total of 5 characters. Whereas packing it as(a)(ba)(ba)(b\) avoids the need to escape anything, and the packed string is 4 characters.)
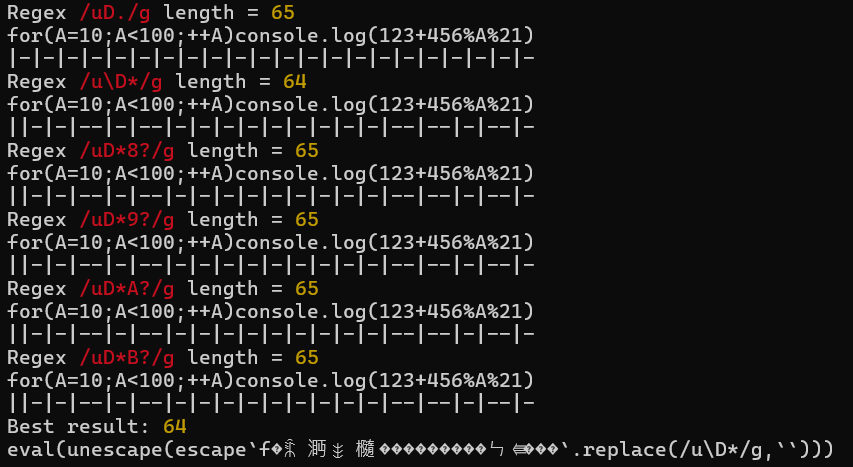
The packer also makes an effort to find the regex with best results. Each of these regexes will be checked:
/uD./g/u\D*/g/uD*X?/gfor some X in 8–B/uD+X?/gfor some X in 8–B (excluded if (3) works)/uD[XY]/gfor some X in 8–B, Y in C–F (excluded if (1) works)
To help you identify which 3:1 opportunities are being used and missed, the packer will print a breakdown for each tested regex.
Writing packable code
With a fixed-rate packer like the traditional 2:1, the shortest solution in bytes leads to the shortest packed solution. However, with the variable-rate 2:1-plus packer, that’s no longer true. For example, the expression 11**5 is the shortest representation of 161051. This requires 3 characters to pack: there are no opportunities for a 3:1 pack, so (11)(**)(5) is the best we can do. However, the expression 161051 itself can be packed into 2 characters, because 161 and 051 can both be done as a 3:1 pack. (This is a contrived example, but it happens in real golf code, too: I’ve had at least two solutions on code.golf where my best packed solution corresponds to a longer bytes solution.) So, it can be worth looking for opportunities to use longer mathematical expressions that pack better.
Some other tips to get the most out of the packer:
- For numbers with exponential notation, use a capital E instead of lowercase:
1e3↦1E3. - Prefer the
%operator over equivalents:A&15↦A%16. - The 3:1 packing opportunities require certain alignment. Review the packer’s output to see where there may be missed opportunities. See if you can rearrange your code to create the correct alignments. For example,
y=10;x=z%4requires 5 characters to pack as(y=)(10)(;x)(=z)(%4)or(y)(=1)(0;)(x=)(z%4), butx=z%4;y=10can be packed in 4 as(x=)(z%4)(;y)(=10). Recall that the 3:1 opportunities with the regex/u\D*/gare of these forms:[any ASCII][%][any digit][%][any digit][any ASCII][any ASCII][any hex digit][any hex digit][%][any digit][%][any digit](4:1)
Hope you enjoyed this deep dive into packing. Good luck with your golfing!